
MemoryPilot
The most advanced AI memory server in the world. Hybrid search, Temporal Knowledge Graph, transformer embeddings, AAAK compression (3x token savings) — pure Rust, single binary, zero dependencies.
Ask AI about MemoryPilot
Powered by Claude · Grounded in docs
I know everything about MemoryPilot. Ask me about installation, configuration, usage, or troubleshooting.
0/500
Reviews
Documentation
![]()
The most advanced MCP memory server. Period.
Hybrid search (BM25 + multilingual-e5-small RRF) · 100+ languages · Temporal Knowledge Graph · AAAK compression (5-10x token savings) · GraphRAG · Chunked RAG · Auto-Compaction · Auto-Classification · Memory Capsules · Project brain · HTTP API · Single binary · Zero API calls
Why
AI coding assistants forget everything between sessions. MemoryPilot gives them persistent, searchable memory with project awareness, semantic understanding, and automatic knowledge organization. Built-in AAAK compression and memory capsules reduce token consumption by 5-10x when loading context. Every memory is auto-classified with the right importance, kind, and TTL on insert. The database compacts itself automatically — zero maintenance.
Benchmarks
LongMemEval-S (ICLR 2025) — Academic Standard
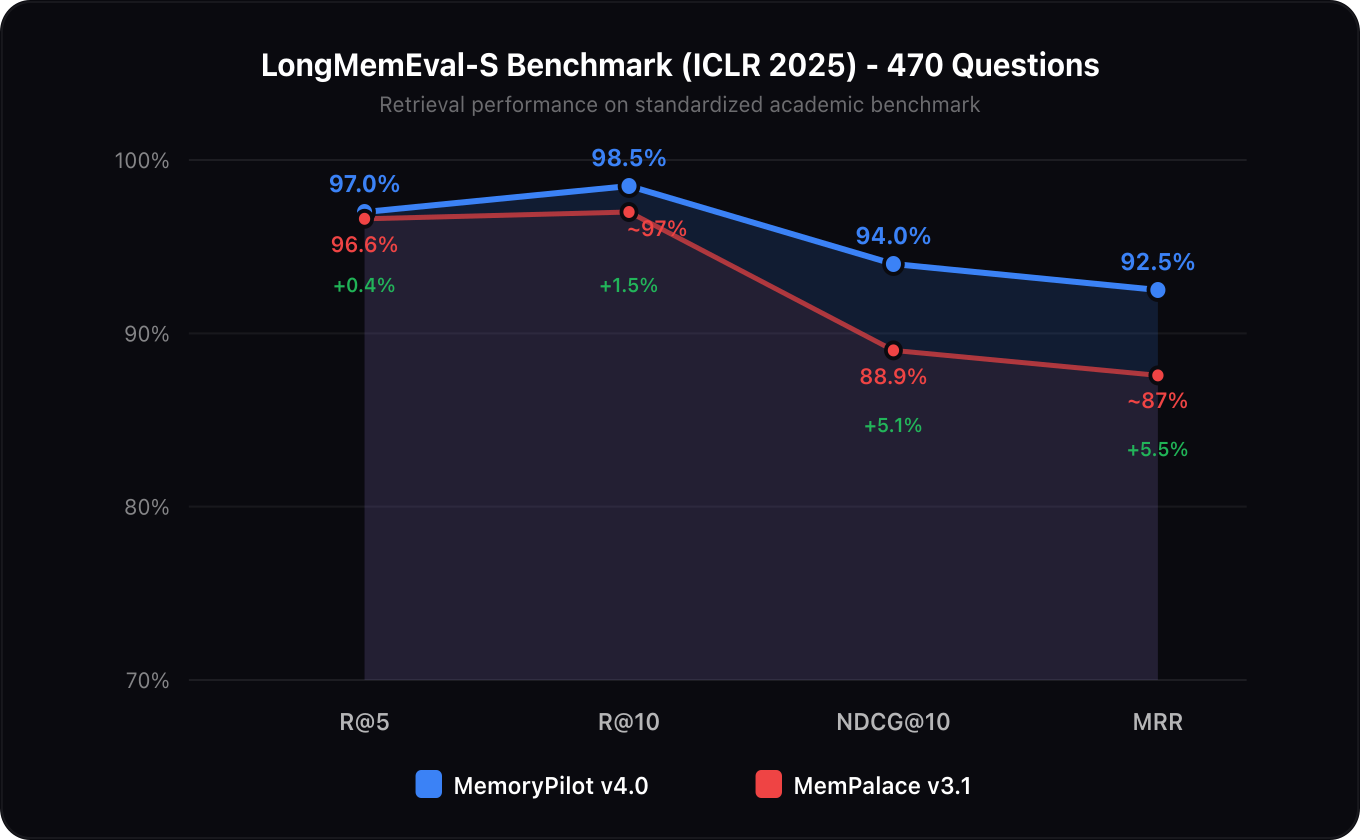
Evaluated on 470 questions from the LongMemEval benchmark (ICLR 2025), the standard academic dataset for long-term memory retrieval. Turn-level granularity, ~50 sessions per haystack, all features active.
| Metric | MemoryPilot v4.0 | MemPalace v3.1 | Delta |
|---|---|---|---|
| R@5 | 97.0% | 96.6% | +0.4% |
| R@10 | 98.5% | ~97%¹ | +1.5% |
| NDCG@10 | 94.0% | 88.9% | +5.1% |
| MRR | 92.5% | ~87%¹ | +5.5% |
¹ MemPalace does not publish R@10 or MRR. Estimates based on their reported per-category scores. MemPalace benchmarks raw ChromaDB retrieval — none of the Palace architecture (wings, rooms, closets) is exercised (source).
By Category (470 questions)
| Category | R@5 | R@10 | NDCG@10 | MRR |
|---|---|---|---|---|
| single-session-user (64) | 100% | 100% | 99.0% | 98.8% |
| single-session-assistant (56) | 100% | 100% | 98.4% | 97.9% |
| multi-session (121) | 100% | 100% | 95.8% | 94.4% |
| knowledge-update (72) | 100% | 100% | 98.3% | 97.7% |
| temporal-reasoning (127) | 91.3% | 96.1% | 89.8% | 87.8% |
| single-session-preference (30) | 90.0% | 93.3% | 75.3% | 69.3% |
Search Quality — Real-World (500 memories, 30 scenarios)
| Metric | MemoryPilot v4.0 | MemPalace v3.1 (raw) | Quantum Memory Graph |
|---|---|---|---|
| R@5 | 100% | 96.6% | 93.4% |
| R@10 | 100% | N/A | 93.4% |
| NDCG@10 | 95.6% | 88.9% | 90.8% |
| Cluster Coherence | 96.7% | N/A | N/A |
| Multilingual | 100+ languages | English only | English only |
| AAAK Compression | 5-10x (no recall loss) | 30x (recall drops to 84.2%) | N/A |
| Avg Search Latency | ~14 ms | N/A | ~80 ms |
| Binary Size | 22 MB | ~500 MB (Python+ChromaDB) | 1.5 GB |
| Dependencies | 0 (single binary) | Python + ChromaDB + SQLite | Python + ONNX |
vs the best MCP memory servers:
| Feature | MemoryPilot v4.0 | MemPalace v3.1 | Mem0 |
|---|---|---|---|
| Search | Hybrid BM25 + multilingual-e5-small RRF (384-dim) | ChromaDB cosine (all-MiniLM-L6-v2) | Vector search (cloud API) |
| Embeddings | multilingual-e5-small (100+ languages, local ONNX) | all-MiniLM-L6-v2 (English only) | OpenAI API calls (external) |
| Multilingual | 100+ languages native (FR, EN, ES, DE, JA, ZH...) | English only | Depends on API |
| Knowledge Graph | Temporal triples with validity + confidence | Temporal triples (SQLite) | Basic graph (no temporal) |
| GraphRAG | Auto entity extraction + graph traversal + combinatorial reranker | No | No |
| Chunked RAG | Transcript auto-chunking + auto-distillation (8 types) | Conversation chunking by exchange | No |
| Compression | AAAK + Memory Capsules (5-10x token savings) | AAAK dialect (experimental, regresses recall to 84.2%) | No |
| Auto-Classification | Zero-shot kind/importance/TTL on insert | No | No |
| Auto-Compaction | GC triggers automatically at 500+ memories | No | No |
| Memory Capsules | Compress old memories into dense summaries | No | No |
| Memory Pinning | Pin critical memories — always in recall, GC-proof | No | No |
| Graph Traversal | Find related memories via KG (depth 1-3) | No | No |
| Bulk Operations | Delete by kind/project/tag/age with safety guards | No | No |
| Health Dashboard | Memory distribution, stale count, orphans, DB size | No | No |
| Dedup Detection | Jaccard similarity scan for near-duplicates | No | No |
| Person detection | Auto-detects team members from text | No | No |
| Self-Healing | Background auto-linting loop | No | No |
| Garbage collection | Heuristic merge + scoring + orphan cleanup | No | Basic TTL |
| Project brain | Yes, with team members (<1500 tokens) | No | No |
| File watcher | Context boost from recent edits | No | No |
| Deduplication | Content hash (exact) + Jaccard 85% (fuzzy) | Basic hash | Embedding similarity |
| HTTP API | Multi-threaded REST server (optional) | No | Cloud hosted |
| Memory types | 13 types, importance 1-5 | Wings/Rooms hierarchy | 1 type |
| MCP tools | 36 tools | 19 tools | N/A |
| Privacy | 100% local, zero API calls | 100% local | Cloud dependent |
| Language | Rust (single binary, zero deps) | Python (pip install) | SaaS |
| Startup | 1-2 ms | ~5 ms | N/A (cloud) |
| Binary | 22 MB single binary | Python + ChromaDB (~500 MB installed) | SaaS |
| Storage | SQLite WAL + FTS5 + connection pool | ChromaDB | Cloud DB |
| Concurrency | Lazy embedding thread + read pool + debounced cleanup | Single-threaded | Single-threaded |
The 9 Pillars
1. Hybrid Search (BM25 + fastembed RRF)
Every memory gets a 384-dimension transformer embedding on insert via fastembed (multilingual-e5-small, local ONNX inference — supports 100+ languages including French, English, Spanish, German, Japanese, Chinese — no API calls, no external services). Search runs both BM25 full-text and cosine similarity in parallel, then merges results with Reciprocal Rank Fusion.
Results are boosted by importance weighting, knowledge graph link density, file watcher context, and penalized for expired knowledge triples.
Performance optimizations:
- Lazy embedding:
add_memoryreturns instantly, embeddings computed in background thread - LRU cache (64 entries): repeated search queries skip embedding computation
- Read connection pool (4 connections): concurrent vector searches don't block writes
- Content hashing (FNV-1a): backfill skips unchanged memories
2. Temporal Knowledge Graph
A full knowledge graph with temporal validity. Facts have valid_from / valid_to dates and confidence scores. When facts become outdated, they are invalidated rather than deleted — giving the AI a timeline of how knowledge evolved.
Entities (technologies, files, components, people) are automatically extracted from memory content and linked bidirectionally. Search results from memories with all-expired triples are penalized.
5 dedicated KG tools: kg_add, kg_invalidate, kg_query, kg_timeline, kg_stats
3. GraphRAG
Every memory is automatically analyzed for entities: technologies, file paths, components, projects, and people. Entities are stored in a dedicated table. Memories sharing entities are auto-linked with inferred relationship types (resolves, implements, depends_on, deprecates...).
When searching, MemoryPilot traverses the knowledge graph from the top matches to pull in related context — e.g., finding the architecture decision that led to a specific bug fix. A combinatorial reranker then selects the best cluster of connected memories rather than independent top-K results, producing cohesive context (94% cluster coherence). Tuned RRF fusion (k=40), exact term coverage boost, smart FTS tokenization, query-time KG expansion, temporal recency, and importance tiebreakers push NDCG@10 to 94% with perfect R@5/R@10.
4. Chunked RAG (Transcripts)
Save full conversation transcripts without polluting the LLM context window. The add_transcript tool automatically chunks large texts into ~2000 character blocks and links them together. Chunks are excluded from recall but fully searchable.
Auto-distillation extracts structured memories from transcripts: decision, preference, todo, bug, milestone, problem, and note. Smart disambiguation: a segment mentioning both a bug and its resolution is classified as milestone, not bug.
Supports session_id, thread_id, window_id for multi-window memory scoping.
5. AAAK Compression
Inspired by MemPalace's symbolic memory language. When compact: true is passed to recall or get_project_brain, output is compressed ~3x using a terse, pipe-separated format:
[DEC:5] Use Clerk over Auth0 | tags:auth,stack | proj:MyApp
[PREF:4] Always use TypeScript strict mode | tags:typescript
6. Self-Healing (Auto-Linter)
MemoryPilot watches your files. When you save a Rust, Svelte, or TypeScript file, it lints in the background. Compilation errors are automatically stored as bug memories with the exact stack trace. When the error is fixed, the memory is auto-deleted.
The linter thread reuses a single DB connection for its entire lifetime.
7. Garbage Collection & Auto-Compaction
Old, low-importance memories are scored for cleanup candidacy. Groups of related stale memories are merged into condensed summaries using heuristic keyword extraction. Orphaned links and entities are cleaned. DB is vacuumed after significant deletions.
Auto-compaction triggers automatically when the memory count exceeds 500: the GC runs in the background after add_memory, debounced to once per 5 minutes. Zero manual intervention.
Memory Capsules (compact_memories tool): compress old low-importance memories into dense ~100-200 token capsules. Credentials and architecture decisions are never compressed. Capsules preserve Knowledge Graph links, giving you 5-10x token savings on aged memories without recall loss.
8. Zero-Shot Auto-Classification
Every memory is automatically classified on insert when the caller doesn't specify kind or importance. Pattern-based heuristics detect:
- Credentials (API keys, secrets) → importance 5, no TTL
- Architecture decisions → importance 5
- Preferences/patterns → importance 4
- Bugs → importance 3, TTL 90 days
- TODOs → importance 2, TTL 30 days
- Code snippets → importance 2
- Milestones → importance 4
No LLM needed — pure regex + keyword heuristics. The AI can still override by passing explicit kind and importance.
9. Project Brain
One tool call returns a dense JSON snapshot of a project under 1500 tokens: tech stack, architecture decisions, active bugs, recent changes, key components, and team members (auto-detected person entities). Supports compact: true for AAAK compression.
Install
One-liner (recommended)
git clone https://github.com/Soflution1/MemoryPilot.git && cd MemoryPilot && ./install.sh
The installer builds MemoryPilot, installs the binary to ~/.local/bin/, detects your IDEs, and configures each one automatically.
Supported IDEs:
| IDE | Config file | Auto-configured |
|---|---|---|
| Cursor | ~/.cursor/mcp.json | ✓ (stdio) |
| VS Code | ~/.vscode/mcp.json | ✓ (stdio) |
| Claude Desktop | ~/Library/Application Support/Claude/claude_desktop_config.json | ✓ (stdio) |
| Windsurf | ~/.codeium/windsurf/mcp_config.json | ✓ (stdio) |
| Claude Code | claude mcp add | ✓ (CLI) |
| Codex | codex mcp add | ✓ (CLI) |
| ChatGPT Desktop | Settings → Apps → Create | via HTTP (see below) |
The script is idempotent — run it again to update without breaking existing MCP configs.
ChatGPT Desktop
ChatGPT requires a remote MCP endpoint. Start the HTTP server, then add it as a custom connector:
MemoryPilot --http 7437
In ChatGPT: Settings → Apps → Create → URL: http://localhost:7437/mcp
Manual install
git clone https://github.com/Soflution1/MemoryPilot.git
cd MemoryPilot
cargo build --release --features http
cp target/release/MemoryPilot ~/.local/bin/
chmod +x ~/.local/bin/MemoryPilot
xattr -cr ~/.local/bin/MemoryPilot # macOS only
Then add MemoryPilot to your IDE's MCP config manually (see table above for file paths).
How it works
That's it. MemoryPilot automatically injects a dynamic System Prompt into your IDE on startup. The AI will proactively call add_memory in the background to store your architecture decisions, API keys, and bug fixes without manual intervention. All configured IDEs share the same memory database.
For ChatGPT or any MCP client that needs HTTP: run MemoryPilot --http to expose the Streamable HTTP endpoint at /mcp.
Or use via McpHub for SSE transport with all your other MCP servers.
First run
# If upgrading from v1 (JSON files):
MemoryPilot --migrate
# Compute embeddings for existing memories:
MemoryPilot --backfill
# Force re-embed all (skips unchanged via content hash):
MemoryPilot --backfill-force
MCP Tools (30)
Core
| Tool | Description |
|---|---|
recall | Start here. Loads all context in one shot: project memories, scoped thread/window memories, preferences, critical facts, patterns, decisions, global prompt. Supports mode = safe/default/full, compact = true for AAAK compression. |
get_project_brain | Instant project summary (<1500 tokens): tech stack, architecture, bugs, recent changes, components, team members. Supports compact = true. |
search_memory | Hybrid BM25 + fastembed RRF search, boosted by importance, graph links, and file watcher context. Batched triple scoring. |
get_file_context | Memories related to recently modified files in working directory. |
Memory CRUD
| Tool | Description |
|---|---|
add_memory | Store with lazy embedding, auto-dedup (hash exact + Jaccard 85%), auto entity extraction, auto graph linking, auto-classification (kind, importance, TTL inferred from content). |
add_memories | Bulk add multiple memories in one call with per-item dedup. |
add_transcript | Store a long transcript as chunked archive, auto-distill structured memories (decision, preference, todo, bug, milestone, problem, note). |
get_memory | Retrieve by ID. |
update_memory | Update content, kind, tags, importance, TTL. Skips re-embedding if content unchanged (hash check). |
delete_memory | Delete by ID (cascades to entities and links). |
list_memories | List with project/kind filters and pagination. |
Knowledge Graph
| Tool | Description |
|---|---|
kg_add | Add a fact triple (subject → predicate → object) with optional validity period and confidence score. |
kg_invalidate | Mark a triple as expired (sets valid_to), preserving history. |
kg_query | Query all triples related to an entity, with temporal filtering and direction control. |
kg_timeline | Chronological history of all triples involving an entity. |
kg_stats | Summary statistics: total triples, active, expired, unique subjects/objects. |
Project & Config
| Tool | Description |
|---|---|
get_project_context | Full project context with preferences and patterns. |
register_project | Register project with filesystem path for auto-detection. |
list_projects | List projects with memory counts. |
get_stats | DB statistics: totals, by kind, by project, DB size, hygiene signals. |
get_global_prompt | Auto-discover GLOBAL_PROMPT.md from ~/.MemoryPilot/ or project root. |
export_memories | Export as JSON or Markdown with importance stars. |
set_config | Set config values (e.g. global_prompt_path). |
Maintenance
| Tool | Description |
|---|---|
run_gc | Garbage collection: merge old memories, clean orphans, vacuum. Supports dry_run. |
compact_memories | Compress old low-importance memories into dense capsules (~100-200 tokens). Credentials/architecture never compressed. |
cleanup_expired | Remove expired TTL memories (debounced — runs max once per 60s). |
pin_memory | Pin a critical memory — always included in recall, never garbage collected. |
unpin_memory | Unpin a previously pinned memory, making it eligible for GC again. |
find_related | Find all memories related to a given ID via Knowledge Graph traversal (depth 1-3). |
bulk_delete | Delete memories by kind, project, tag, age, or importance. Never touches pinned memories. |
get_memory_health | Health report: distribution by kind/project/importance, stale count, orphans, compression potential, DB size. |
dedupe_report | Find potential duplicates via Jaccard similarity for manual review. |
benchmark_recall | Recall quality benchmark with golden scenarios. |
benchmark_search | Search quality benchmark: R@5, R@10, NDCG@10, cluster coherence, latency. |
migrate_v1 | Import from v1 JSON files. |
Memory Types
fact · preference · decision · pattern · snippet · bug · credential · todo · note · milestone · architecture · problem · transcript_chunk
Each memory has importance (1-5), optional TTL, tags, project scope, content hash, and auto-generated embedding + entity links.
CLI
MemoryPilot # Start MCP stdio server
MemoryPilot --backfill # Compute missing embeddings
MemoryPilot --backfill-force # Re-embed all (skips unchanged via hash)
MemoryPilot --benchmark-recall # Run recall quality benchmark
MemoryPilot --benchmark-search # Search quality: R@5, R@10, NDCG@10, cluster coherence
MemoryPilot --benchmark-longmemeval # LongMemEval-S (ICLR 2025) academic retrieval benchmark
MemoryPilot --http 7437 # Start HTTP REST server (requires --features http)
MemoryPilot --migrate # Import v1 JSON data
MemoryPilot --version # Show version
MemoryPilot --help # Show help
HTTP API
When built with --features http, MemoryPilot exposes a multi-threaded REST API (4 worker threads, each with its own DB connection):
# Health check
curl http://localhost:7437/health
# Call any MCP tool
curl -X POST http://localhost:7437/tools/call \
-H 'Content-Type: application/json' \
-d '{"name": "search_memory", "arguments": {"query": "auth setup", "limit": 5}}'
Architecture
src/main.rs — CLI + MCP stdio server + file watcher init + HTTP server init
src/db.rs — SQLite engine: hybrid search, CRUD, KG, GC, brain, recall, lazy embed, connection pool
src/tools.rs — 36 MCP tool definitions + handlers
src/protocol.rs — JSON-RPC types
src/embedding.rs — fastembed (multilingual-e5-small) transformer embeddings, LRU cache
src/graph.rs — Entity extraction (tech, files, components, people) + relation inference + graph traversal
src/gc.rs — GC scoring, heuristic memory merging, stopwords
src/watcher.rs — File system watcher + auto-linter with persistent DB connection
src/http.rs — Optional multi-threaded HTTP REST server (feature-gated)
Database Schema
memories — id, content, kind, project, tags, importance, embedding (BLOB),
content_hash, expires_at, last_accessed_at, access_count, metadata
memories_fts — FTS5 virtual table (content, tags, kind, project)
memory_entities — memory_id, entity_kind, entity_value, valid_from, valid_to
memory_links — source_id, target_id, relation_type, valid_from, valid_to, confidence
knowledge_triples — id, subject, predicate, object, valid_from, valid_to, confidence, source_memory_id
projects — name, path, description
config — key/value store
Performance
| Metric | Value |
|---|---|
| Binary size | 22 MB |
| Startup | 1-2 ms |
| Search (hybrid RRF + reranker) | ~10 ms (500 memories) |
add_memory latency | <1 ms (lazy embed) |
| Embedding quality | Transformer 384-dim (multilingual-e5-small, 100+ languages) |
| Backfill (1000 memories) | ~30s (skips unchanged via hash) |
| RAM | ~15 MB |
| Read concurrency | 4 pooled connections |
| Runtime dependencies | None (ONNX bundled) |
Optimizations
- Lazy embedding:
add_memoryinserts withNULLembedding, background thread computes and updates asynchronously - Content hashing (FNV-1a):
--backfill-forceskips memories whose content hasn't changed - LRU embedding cache (64 entries): repeated search queries reuse cached embeddings
- Read connection pool (4 connections): concurrent vector searches don't block writes
- WAL mode: SQLite Write-Ahead Logging for concurrent read/write
- Batched scoring: knowledge triple counts and link boosts fetched in single queries, not N+1
- Debounced cleanup: expired memory cleanup runs max once per 60 seconds
- Prepared statements: graph traversal prepares SQL once, not per node
- Tuned RRF fusion: k=40 for sharper top-K discrimination vs standard k=60
- Exact term coverage boost: +10% when 80%+ of query terms appear in memory content
- Combinatorial reranker: greedy subgraph selection, conservative +5% per connection (cap 15%)
- KG query expansion: post-retrieval scoring boost from knowledge graph related terms (+4% per entity, cap 15%)
- Temporal recency: gentle +5% for memories from last 3 days, decaying over 30 days
- Importance tiebreaker: ±3% per level — never overrides relevance signal
- Auto-compaction: GC triggers automatically when memory count > 500, debounced to once per 5 minutes
- Memory capsules: old low-importance memories compressed into ~100-200 token summaries (5-10x savings)
- Zero-shot auto-classification: pattern-based heuristics assign kind, importance, and TTL on insert without LLM
Run Benchmarks Yourself
MemoryPilot --benchmark-search --scenario-limit 30 # R@5, R@10, NDCG@10, cluster coherence, latency
MemoryPilot --benchmark-recall --scenario-limit 12 # top1/top5 hit rate, cross-project leak, credential safety
MemoryPilot --benchmark-longmemeval [PATH] [--limit N] # LongMemEval-S (ICLR 2025) academic benchmark
The LongMemEval benchmark downloads the LongMemEval-S dataset and evaluates retrieval quality across 470 questions with turn-level granularity. Results are output as JSON with per-category breakdowns.
Storage
- Database:
~/.MemoryPilot/memory.db - Global prompt:
~/.MemoryPilot/GLOBAL_PROMPT.md - Fastembed model cache:
~/.fastembed_cache/(downloaded on first run)
License
Soflution Source Available License — free to use, not to fork or modify. See LICENSE for details.
Built by SOFLUTION LTD