
PodBit
Autonomous Discovery Engine
Ask AI about PodBit
Powered by Claude · Grounded in docs
I know everything about PodBit. Ask me about installation, configuration, usage, or troubleshooting.
0/500
Reviews
Documentation
![]()
Podbit
Do you want to make a discovery?
AI has nothing to say unless you ask the question. Podbit discovers the questions.
A genetic algorithm that breeds knowledge into verified insight. It combines your research, the LLM's training knowledge, and live web research - then evolves them through multiple generations.
Autonomous Knowledge and Research Synthesis Engine
Watch overview
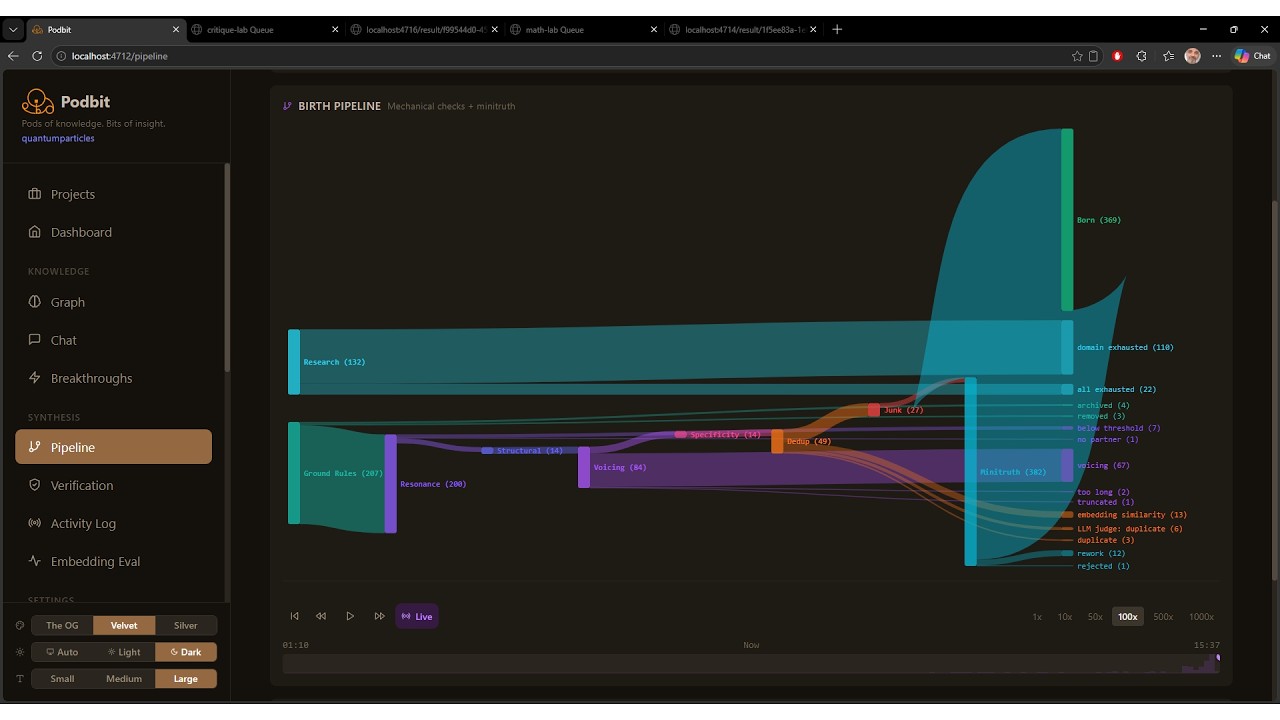
Example Findings
See podbit_elite_nodes.md for a registry of reviewed synthesis nodes — the kind of output Podbit produces.
Early release - actively in development. Podbit is under heavy iteration. Expect rough edges, schema migrations, and parameters that are added/removedmove between releases.
Quick Start
Tested on Windows 11. Podbit is written in cross-platform TypeScript on top of Node.js, SQLite, and tsx, so it should run on macOS and Linux without changes - but those targets have not been exercised yet. If you try it on another OS, you may need to file bugs (and please do).
1. Install Podbit
git clone https://github.com/hexitex/PodBit.git podbit
cd podbit
npm install
cd gui && npm install && cd ..
2. Install the labs (optional but strongly recommended)
The lab fleet lives in a sibling repo, podbit-labs. Clone it next to Podbit so the orchestrator can auto-discover it:
cd ..
git clone https://github.com/hexitex/podbit-labs.git
cd podbit-labs
npm install # installs root + workspace deps
cd lab-core && npm install && cd ..
cd math-lab && npm install && cd ..
cd nn-lab && npm install && cd ..
cd critique-lab && npm install && cd ..
You should end up with this layout:
<parent>/
├── podbit/ # Podbit core
└── podbit-labs/
├── lab-core/ # shared infrastructure
├── math-lab/ # computational verification
├── nn-lab/ # neural network experiments
└── critique-lab/ # LLM critique
Podbit finds the labs via PODBIT_LABS_ROOT (defaults to ../podbit-labs). Each lab is autodetected, and you can opt them into orchestrator-managed startup by setting LAB_MATH_AUTOSTART=true / LAB_NN_AUTOSTART=true / LAB_CRITIQUE_AUTOSTART=true in .env. Without the labs sibling repo Podbit still runs - verification just stays disabled until you register a lab.
3. Start everything
cd ../podbit
npm run orchestrate
Open http://localhost:4712 for the GUI. The API server runs on http://localhost:4710 and the knowledge proxy on http://localhost:11435. (All ports are configurable via .env - see config/port-defaults.json.)
For LLM IDE agent integration, the MCP server auto-starts via .mcp.json:
npm run mcp
Requirements: Node.js >= 18, any OpenAI-compatible LLM provider (LM Studio, Ollama, OpenAI, Anthropic, Z.AI). A dedicated embedding model is required (any Ollama / LM Studio compatible embedder works).
Recommended starting point: local LLMs
The easiest way to get going - and the cheapest while you're learning the system - is to point every subsystem at a local LLM via LM Studio or Ollama. No API keys, no per-token cost, fast iteration, and you can leave the autonomous cycles running overnight without watching a meter.
That said, local models are not strong enough for the subsystems marked as Frontier tier in the Agent Subsystems table - voice, chat, research, docs, tuning_judge, breakthrough_check, spec_extraction, and spec_review need real reasoning quality. Running these on a 7B-13B local model produces shallow voicings, unfaithful spec extraction, and breakthrough scores that miss the point. The Models page in the GUI shows each subsystem's tier so you know which calls deserve a frontier model.
A practical hybrid setup:
- Frontier tier → a paid frontier model (Claude, GPT, Z.AI GLM-4.6, etc.) - used sparingly, only on the calls that matter
- Medium / Small tier → a capable local model (Qwen 2.5 32B, Llama 3.3 70B, etc. via LM Studio/Ollama) - handles the volume work
- Embedding → a local embedding model (nomic-embed-text, mxbai-embed-large) - runs constantly, must be local for cost reasons
You can start with everything on local, see where the output quality breaks down, and selectively promote individual subsystems to a frontier model from the GUI Models page. Per-subsystem assignment is the whole point of the architecture - use it.
Podbit is an autonomous Knowledge and Research Synthesis Engine.
You feed it knowledge - papers, notes, code, raw ideas - and it runs a continuous cycle of synthesis, verification, and discovery to find connections you didn't know existed. It is not a RAG system. It uses RAG - but as a delivery mechanism for knowledge it has synthesised and verified, not as its core function.
What Podbit Does
Podbit ingests knowledge, then autonomously:
- Discovers connections between ideas across domains using embedding-guided pair selection and LLM synthesis
- Generates research questions from tensions between conflicting nodes
- Verifies claims via a fleet of external lab servers (computational, neural, and critique) with adversarial spec review to catch tautological tests
- Accumulates validated findings in a curated Elite Pool that undergoes generational synthesis
- Delivers knowledge to any LLM consumer via a Knowledge Delivery Proxy and MCP tools
Seven autonomous cycles run in parallel - synthesis, validation, questions, tensions, research, autorating, and lab verification - each exploring a different facet of your knowledge graph. Every mutation is journaled, so the entire graph can be rolled back to any point in time without losing curated work.
Architecture
1. Knowledge Graph
The research substrate. Every piece of knowledge lives as a typed, weighted, embedded node connected by parent-child edges in a directed acyclic graph (DAG).
Node types: seed (curated input), synthesis (auto-generated), voiced (guided synthesis), breakthrough (validated insight), possible (pre-breakthrough candidate), elite (EVM-verified), question (research gap), raw (uncurated RAG material)
Weight represents accumulated importance (starts at 1.0, unbounded). Breakthroughs are boosted to 1.5; their parents gain +0.15, grandparents +0.05. Salience controls sampling frequency and decays over time to prevent stale dominance.
Domains & Partitions: Nodes belong to domains, grouped into partitions. Nodes in different partitions cannot synthesise together unless explicitly bridged - preventing cross-contamination. System partitions (e.g. know-thyself for auto-tuning knowledge) are structurally un-bridgeable and isolated by design.
Trajectory classification: Every synthesis node is classified as knowledge (specific, factual - contains numbers, technical terms) or abstraction (general, philosophical - lower initial weight to prevent vague drift).
Lineage Explorer: Every node tracks full parent-child relationships. The GUI provides a 1-hop detail panel and a multi-generation modal (up to 4 generations deep) using recursive CTE queries.
Merkle DAG Integrity: Every node has a SHA-256 content hash computed from its immutable identity fields (content, type, contributor, creation time, sorted parent hashes), forming a tamper-evident Merkle DAG. A hash-chained integrity log records every lifecycle event.
2. Synthesis Engine
The core research loop. Inspired by genetic algorithm theory, it supports multi-parent recombination (up to 4 parents), niching (domain diversity protection), partition migration (island model cross-pollination), usage-based synthesis decay (fitness pressure), and quantum-inspired cluster selection (simulated annealing for optimal node groupings).
Unified pipeline: Mechanical birth checks plus citizen validation (accept/rework/reject LLM call). Population control via a single comprehensive consultant call evaluating coherence, grounding, novelty, specificity, and forced analogy detection. 100+ configurable parameters.
Synthesis cycle:
- Sample 2+ nodes by salience-weighted selection
- Gate on cosine similarity (configurable band, default 0.3-0.85)
- Voice connection via LLM
- Pass through quality pipeline (consultant or heuristic mode)
- Create new child node with parent edges and full provenance
3. Lab Verification Framework
Podbit verifies claims by routing them to independent lab servers that never see the claim narrative - only a structured experiment specification. This is the system's defence against bias: the lab cannot know which result would "please" the synthesis engine.
Pipeline (Podbit side):
- Pre-flight skip check - if a prior attempt found no lab capable of testing this
specType, the pipeline aborts before any LLM call - Spec Extraction (
spec_extractionsubsystem) - LLM reads the claim plus published lab capabilities and produces a declarativeExperimentSpec. Prior rejection reasons are injected so retries converge instead of flip-flopping. This is the only auditable bias surface - Structural tautology check - rejects specs containing embedded code, function definitions, or multi-line implementations. Specs must be parameters, not implementations
- Falsifiability review (
spec_reviewsubsystem) - adversarial LLM reads the spec and asks "could these parameters be cherry-picked to guarantee the claimed result?" Catches rigged parameterisation that survives the structural check - Lab routing (
lab_routingsubsystem) - when multiple labs match the spec type, an LLM picks the best one based on capabilities, queue depth, health, and priority - Submission and freeze - node is frozen for the duration of the experiment to prevent concurrent mutation; auto-unfrozen on completion or
freezeTimeoutMs - Verdict and consequences - Podbit applies graph effects: weight adjustment, taint propagation (BFS through descendants on refute), evidence storage, elite promotion at ≥95% confidence
Lab fleet: Each lab is a standalone Node.js service with its own SQLite database, its own LLM assignments, its own queue, and a uniform HTTP contract (/health, /capabilities, /submit, /status/:id, /result/:id, /artifacts/:id[/:file]). Labs are registered in the system database and auto-discovered via periodic capability pings. The orchestrator can spawn each lab as a managed service with health checks and auto-restart.
| Lab | Purpose | Spec types it accepts |
|---|---|---|
| math-lab | Computational verification - generates Python, runs in a sandbox, evaluates its own results | numerical, algebraic, statistical, simulation |
| nn-lab | Neural network training experiments - declarative architecture/training specs, runs PyTorch jobs | training, architecture comparison, ablation |
| critique-lab | Pure LLM critique - no computation, no sandbox - evaluates quality, specificity, novelty, falsifiability | qualitative, structural, expert review |
Labs are extensible. The HTTP contract is the entire interface - anything that speaks it can be a lab. The shared @lab/core package gives you queue management, artifact zipping, health reporting, and SQLite persistence out of the box, so a new lab is mostly the codegen prompt and the runner. Build labs for chemistry simulation, physics solvers, theorem provers, biological assays, web scrapers, on-chain queries, hardware-in-the-loop rigs - anything that can take a declarative spec and return a verdict. Once a lab publishes its specType capabilities, the spec extractor can target it and the router will find it automatically. The point is to grow the verification surface horizontally rather than overload one general-purpose checker.
Artifact pull: On completion, Podbit downloads a zip of the lab's full audit trail (codegen prompts, generated code, stdout/stderr, evaluation prompts, intermediate artifacts) and stores it in lab_evidence. The Verification page in the GUI serves these artifacts directly so every verdict is fully reviewable.
API Registry grounding: Before submission, the spec extractor can call into a registry of external APIs (PubChem, UniProt, CrossRef, Semantic Scholar, Materials Project, IBM RXN, plus user-defined endpoints) to fetch authoritative values. API modes: Verify (fact-check and adjust node weight), Enrich (extract new knowledge as child nodes), or Both.
Number Variable Registry: All numeric values are extracted from nodes at creation time and replaced with opaque [[[PREFIX+nnn]]] tokens (e.g. [[[SBKR42]]]). The synthesis engine works structurally with variable references; a legend explains each token in voicing prompts. Values are resolved back to real numbers for all other LLM paths (compression, chat, EVM). This prevents domain-specific constants from being universalised across synthesis domains.
Elite Verification Pool: Nodes verified at ≥95% confidence (or confirmed by consultant review) are promoted to a curated, ever-growing pool. Elite-to-elite bridging is the highest-priority synthesis task - pairing lab-verified findings to produce progressively refined insights across generations. Each generation produces increasingly distilled knowledge. Terminal nodes at max generation represent findings requiring empirical validation outside the system. Elite nodes are mapped against project manifest goals; the coverage report shows which research goals have verified evidence and which remain gaps.
Breakthrough Registry: A permanent shared record of all validated discoveries across all projects. Promotions are scored on four dimensions (synthesis, novelty, testability, tension resolution - each 0-10). The registry persists content snapshots, all four scores, parent node contents, promotion source, and project context.
Node Lifecycle: A fertility-driven state machine manages node health: nascent → active → declining → composted. Graph health metabolism is tracked on the Dashboard.
4. Graph Journaling & Time-Based Rollback
Every mutation to the graph is captured by SQLite triggers on the core tables (nodes, edges, partitions, number registry). The journal lets you roll the entire graph back to any point in time by replaying entries backwards.
Pinning: Curated work - voiced syntheses, breakthroughs, elite nodes - can be pinned. A pin exports the node and its full ancestry chain; on rollback, pinned content is reimported with its original timestamps via INSERT OR IGNORE so a destructive rewind cannot lose validated insights.
Timeline markers are emitted on high-impact events (config changes, KB scans, dedup runs, lab verdicts) so the timeline reads as an annotated history rather than a flat ledger. The GUI Journal Timeline page renders the markers, lets you preview a rollback, and shows which nodes would be deleted, modified, or preserved.
Exposed via the podbit.journal MCP tool and /api/journal/* REST routes.
5. Supporting Infrastructure
Knowledge Base: Ingest research material - papers, documents, code, data - via 6 reader plugins (Text, PDF, Doc, Sheet, Image, Code) with real-time file watching (chokidar), SHA-256 change detection (skips unchanged files on re-scan), smart chunking, and automatic embedding. Document readers (PDF, Doc, Text) use a two-stage decomposition pipeline: Stage 1 decomposes each section into atomic classified claims, Stage 2 filters and assigns weights for graph ingestion. Raw mode stores files without LLM curation for large reference corpora - raw nodes are queryable for RAG retrieval but excluded from synthesis cycles. The Knowledge Base also includes autonomous LLM researchers that generate foundational domain knowledge directly into the graph, and a human interface via the Chat page for seeding knowledge conversationally.
Context Engine: Session-aware, cross-session learning system that enriches LLM conversations with graph knowledge. Persists topic weights and node usage across sessions; new sessions warm-start from prior conversation patterns. Dynamic token budget allocation with configurable reserve percentages.
Transient Partitions: Visitor partition lifecycle - import, quarantine scanning, synthesis, and departure. Enables temporary cross-instance knowledge exchange.
6. Output Interfaces
MCP Server (mcp-stdio.ts): Standard Model Context Protocol integration for IDE and developer tooling (Cursor, Windsurf, Claude Desktop, VS Code, Zed). Auto-starts the full stack on first connection. Exposes 8 core tools with rich JSON schemas plus a generic podbit.api gateway that gives the agent discovery and execution access to ~25 additional tools (graph ops, synthesis, lab verification, elite pool, journal/rollback, KB ingestion, config tuning, document generation). See the MCP Guide for IDE setup, tool reference, and recipes.
Knowledge Delivery Proxy (proxy-server.ts, port 11435): A fully OpenAI-compatible endpoint. Point any client that speaks the OpenAI API at it and every request is enriched with graph knowledge before forwarding to the LLM - no code changes required. Supports streaming (SSE), tool injection (graph query/propose/promote tools), two injection strategies (complement and replace modes), and dynamic knowledge budget allocation. Falls back gracefully if the model doesn't support tool calling.
REST API & GUI (API on port 4710, GUI on port 4712): Full web dashboard with Dashboard, Chat, Graph Browser, Breakthroughs, Verification, Labs, Knowledge Base, Models, Costs, Prompts, Config, Journal Timeline, Data Management, Pipeline Visualisation, API Registry, Create Docs, and Activity Log.
7. Agent Subsystems (25+)
Each internal subsystem can be assigned a different model - any combination of local (Ollama, LM Studio) or frontier (OpenAI-compatible, Anthropic, Z.AI). Subsystem assignments and inference parameters (temperature, top_p, min_p, top_k, repeat_penalty) are configured independently per subsystem.
| Tier | Subsystems |
|---|---|
| Frontier | voice, chat, research, docs, tuning_judge, breakthrough_check, spec_extraction, spec_review |
| Medium | synthesis, compress, config_tune, autorating, lab_routing, elite_mapping, reader_text/pdf/doc/sheet/code |
| Small | context, keyword, dedup_judge, proxy |
| Dedicated | embedding (dedicated embedding model required), reader_image (vision model required) |
Each lab server (math-lab, nn-lab, critique-lab) also runs its own independent subsystems for codegen and evaluation - assigned and tuned separately so a lab's bias surface stays isolated from the host.
8. Configuration & Auto-Tuning
224 tunable parameters across 34 sections covering synthesis engine behaviour, quality gates, voicing constraints, hallucination detection, dedup, per-subsystem inference parameters, fitness modifiers, GA-inspired features, cluster selection, context engine, lab verification, node lifecycle, transient partitions, and the Elite Pool.
AI Tune: Each config section has an LLM-powered tuning assistant. Describe what you want in natural language (or use presets), review suggested parameter changes with before/after values and explanations, and apply selectively.
Auto-Tune with Gold Standards: Automated parameter search using Latin Hypercube Sampling across a 405-combination grid (25 sampled by default). When prompts are customised, a tuning_judge model generates 3-tier gold standard reference responses (Ideal → 100%, Good → 85%, Acceptable → 65%). Auto-tune scores outputs via embedding cosine similarity against gold standards, using variance-weighted convergence - consistent results beat lucky outliers.
Know Thyself: Config changes, overfitting events, and snapshots are automatically seeded as nodes in a dedicated know-thyself partition. The synthesis engine discovers meta-patterns about what tuning strategies actually work.
Config Snapshots & Audit: Full change history with old/new values, who made the change (human/agent), and reason. Named snapshots for rollback. The podbit.config MCP tool enables fully autonomous tuning workflows.
9. Projects & Portability
Each project is a separate SQLite database - isolated nodes, domains, partitions, synthesis history, and config. Projects can be created via an LLM-guided interview that discovers purpose, domains, goals, and key questions through multi-turn conversation, generating a project manifest that grounds all LLM reasoning.
Partition Export/Import: Partitions are exportable as portable .podbit.json files - the mechanism for sharing curated domain knowledge between projects or between users. Imported nodes get fresh embeddings. Foundation for a future central partition repository.
10. Document Generation
The Create Docs system generates structured research briefs, knowledge syntheses, and technical reports grounded in graph knowledge. Requests are decomposed into sections; each section is generated with relevant graph knowledge injected. Jobs persist and resume from partial state. Output downloads as .md.
Technology Stack
- Runtime: Node.js 18+ with tsx (TypeScript, no build step)
- Backend: TypeScript, Express.js
- Frontend: React, Tailwind CSS, React Query, Vite
- Database: SQLite (better-sqlite3, WAL mode) - one database file per project
- Embeddings: Any Ollama / LM Studio compatible embedding model
- LLM: Any OpenAI-compatible API, Anthropic, Z.AI - per-subsystem assignment
- Protocol: MCP via
@modelcontextprotocol/sdk - Integrity: SHA-256 Merkle DAG with tamper-evident hash-chained log
Integration Surfaces
┌──────────────────────────────────────────────────────┐
│ MCP stdio → IDE agents, Cursor, Windsurf, etc │
│ REST / GUI → localhost:4710 / localhost:4712 │
│ Knwldg Proxy → localhost:11435 (OpenAI-compatible)│
│ Lab fleet → math:4714, nn:4715, critique:4716 │
└──────────────────────────────────────────────────────┘
All share the same knowledge graph,
synthesis engine, and context engine.
Typical Workflow
- Seed knowledge - add seeds via MCP (
podbit.propose), the GUI Chat, or Knowledge Base folder ingestion - Run synthesis - start the engine in API mode (autonomous) or MCP mode (agent-supervised)
- Review and curate - rate nodes, promote breakthroughs, find tensions, remove junk
- Verify claims - Podbit extracts experiment specs and routes them to the lab fleet (math, neural, critique, or any custom lab you build) for independent testing
- Roll back if needed - pin the breakthroughs you care about, then use the Journal Timeline to rewind the graph to any earlier state without losing them
- Explore elite findings - review the elite pool coverage report against your project manifest
- Enrich other tools - point any OpenAI-compatible client at the Knowledge Delivery Proxy
- Tune - use AI Tune or Auto-Tune to optimise synthesis behaviour for your domain and models
- Generate documents - produce structured research briefs grounded in verified graph knowledge
License
AGPL-3.0 © Rob McGlade